
Интрукция по настройке NewsGrabber JC для Joomla
 Автор: Роман Чернышов
Автор: Роман Чернышов  Компонент для Joomla, благодаря которому можно обеспечить свой сайт постоянному авто-наполнению контентом. Достаточно просто настроить источники с которых будет браться информация. Поддерживаются как RSS ленты так и HTML источники. Как и следует из названия NewsGrabber JC, это компонент — полноценный граббер материала, будь то текста или картинок.
Компонент для Joomla, благодаря которому можно обеспечить свой сайт постоянному авто-наполнению контентом. Достаточно просто настроить источники с которых будет браться информация. Поддерживаются как RSS ленты так и HTML источники. Как и следует из названия NewsGrabber JC, это компонент — полноценный граббер материала, будь то текста или картинок.
Несмотря на то, что в интернете достаточно информации по работе и настройки компонента, мне очень часто поступают просьбы, о помощи в работе со столь, на мой взгляд простым инструментом. В связи с чем был написан этот мануал, инструкция или пособие, назвать можно как угодно. Так же я прилагаю два видео ролика и кучу картинок, благодаря которым, надеюсь вы сможете разобраться во всем и не тратить уйму времени на изучение методом тыка.
Требования к хостингу:
- Для работы NewsGrabber необходимо, чтобы хостинг имел установленный ionCube Loader
- Хостинг желательно выбирать подороже и по качественнее. Joomla и без того бывает, что притормаживает на слабых хостах, а тут и вовсе может начать тупить
1. Важно! Принцип работы греббера NewsGrabber JC.
Для начале опишу принцип работы граббера, а именно откуда и какие данные он берет, как он их обрабатывает и какие могут возникать проблемы при его настройке.
Работа с лентой RSS
И так предположим, что уже настроили один источник RSS. Многие ошибочно думают, что новости собираются непосредственно из RSS ленты, такое неправильное понимание работы граббера часто усложняет его настройку.
На самом же деле алгоритм сбора новостей следующий:
1) граббер считывает RSS поток (формат его XML)
2) выделает из RSS потока «Название новости», «Дату новости», «Саму новость», «Автора новости» и самое главное, что нужно грабберу это URL новости, т.е. ссылку по которой находиться полная оригинальная новость (страница, уже в формате HTML).
3) После сбора данных из RSS потока, в зависимости от настроек парсер оставляет только те данные, что нужны для формирования и публикации новости уже непосредственно на самом сайте. Но при этом всегда парсер составляет список адресов (урлов) по которым находятся сами новости.
4) Далее парсер начинает обходить ссылку за ссылкой (полученную из RSS потока), проходя по ссылкам парсер считывает HTML код страницы полной новости, именно из этой страницы и из этого кода (а не из RSS потока) парсер и возьмет саму новость и ее заголовок.
5) И так считав HTML код страницы, парсер как я и написал выделяет из нее уже саму новость с заголовком, применяя к странице соответствующую маску (регулярное выражение), при этом вместе с самим текстом новости захватывается и чать html кода страницы.
6) Помимо текста новости и ее заголовка, парсер умеет собирать картинки к данной новости. Тут так же важно знать, что картинка будет взята лишь в том случае если она расположена в самом тексте новости, если же парсер настроен так, что берет текст новости по определенной маске и при этом не захватывает картинку (ее html код <img src=”путь к картинке” alt=”описание картинки”/>), то считаная она не будет. Сама же картинка в свою очередь считывается парсером следующим образом: если в тексте новости парсер находит html код обозначающий картинку <img src=”путь к картинке” alt=”описание картинки”/>, то он выделяет из этого кода путь к самой картинке на сервере донора, затем просто скачивает ее и сохраняет в указанную папку (задается при настройке), если папка не прописана в настройках ленты, то картинка взята не будет.
7) После того, как текст новости и ее заголовок выделен, картинка сохранена в отельную папочку, парсеру необходимо очистить текст новости от лишних HTML тегов, разного рода ссылок, стилей, js скриптов, затем возможно вставить копирайт в конце новости или еще что либо, в зависимости от его настроек и пожелания админа =)… Все эти действия парсер проделывает в зависимости от того, какие фильтры настроены (фильтр – это по сути команда парсеру, что нужно убрать, вырезать или заменить, причем очередность срабатывания фильтров настраивается, например первое действие – применить фильтр очистки текста новости от ссылок, второй фильтр – заменить весь жирный шрифт на курсивный и т.д.)
8) после того как парсер проделает все манипуляции с текстом, он ее передает на публикацию, или же автоматом публикует на главной странице сайта, в зависимости от настроек.
Работа с лентой HTML
Алгоритм работы парсера с лентой в формате HTML аналогичен RSS, но все же тут имеются свои особенности.
1) Граббер считывает html страницу со списком коротких новостей, (пример: http://www.example.ru/poetry)
2) После считывание кода страницы, парсер должен собрать и подготовить список урлов новостей, но на странице в формате HTML в отличии от RSS потока, очень большое кол-во ненужных, левых не относящихся к теме урлов, по этому в настройках необходимо указывать Маску HREF якоря. Таким образом парсер понимает, где страници с новостями, а где все остальное.
Пример таких ссылок-урлов: http://www.example.ru/poetry/164134
Маска для прсера, по которой он будет определять нужный ли это урл: http:\/\/www.example.ru\/poetry\/\+ d (экранируем слеш, и спец символ +d)
Парметр \+ d обозначает любые цифры от 0 до 9, но не каких символов и букв… В итоге все ссылки http://www.example.ru/poetry/p2 (ведущие на страницы со списком превьюшек) отсеятся.
Далее все пункты работают по тому же принципу что и при RSS режиме
Думаю принцип работы алгоритма парсера понятен, далее будем рассматривать уже конкретный пример, настроим RSS ленты, а затем и HTML.
2. Настраиваем RSS ленту новостей.
На примере источника: http://www.example.ru/xml/rss_poetry.php
Для создания и настройки новой ленты заходим – Компоненты/NewsGrabberJC.Pro/Управление лентами/, жмем кнопку «Новый», после чего можно переходить к настройке

Первая вкладка Общие, подробно вдаваться в описание каждого поля я думаю не стоит, т.к. все поля имеют вполне понятные описания, но все же кое что заслуживает тут внимания, и так:
1. Название ленты, тут все понятно, пишем все что хотим… в нашем примере – Поэзия
2. Адрес RSS ленты, указваем полный удрес: http://www.example.ru/xml/rss_poetry.php
3. Активируем ленты, допускаем к обработке ее парсером.
4. Кодировка ленты, можно оставить Авто, но очень часто парсер автоматические не может распознать кодировку ленты, это происходит аз-за неправильного кода XML. Такое бывает. Для того, чтобы узнать кодировку ленты RSS, достаточно перейти по ее ссылке http://www.example.ru/xml/rss_poetry.php и после того как страница загрузится в браузере (пример — Firefox) зайти ВИД/Исходный код , в самом верху кода будет строка <?xml version=»1.0″ encoding=»windows-1251″?> из которой видно что кодировка ленты windows-1251, ее и следует указать
5. Кодировка самой новости на уже на HTML странице сайта донора, для того, чтобы узнать кодировку достаточно найти в коде ТЕГ <meta http-equiv=»Content-Type» content=»text/html; charset=windows-1251″ /> . Бывает так, что лента имеет кодировку windows-1251 но при этом сам сайт донора и его новости в кодировке UTF-8, этиму пункту стоит уделять внимание. Но как говориться некогда не поздно внести изменения в уже нстроенную ленту, если вдруг на сайте вместо нормальных слов будут каракули… (очевидно что проблема в кодировке)
6. Включения автоматического импорта новостей, CRON, тут все ясно. По началу рекомендую, парсить новости ручками, чтобы наглядно видеть что куда и сколько спарсилось. А уже после того, как появится уверенность в правильной работе парсера выставлять на автомат.
Замечание: Часто бывает, что донор меняет код своих страниц, производит изменение в дизайне и прочее, разумеется после чего кое какие парметры ленты нужно перенастраивать. При работе в режиме автомата, в лучшем случае парсер перестанет собирать новости, а в худшем начнет собирать их криво, в тексте новости будет присутствовать лишний html код, который будет отправляться на публикацию и в результате чего будет страдать дизайн сайта, отображение новостей, валидность страниц, и негативное отношение пользователей и ПС к такому сайту…
7. Интервал frontend/cron импорта (минуты) – тут все понятно.
Вторая вкладка Загрузка, (можно пропустить) редко применяющиеся параметры ленты, в этой вкладке можно задать фильтры для Ссылка на новость, Категории ленты и прочее, там все понятно изложено, и особого внимания заострять там неначем. Но стоит понимать, что новость не будет обрабатывать (загружаться) если попадет под настроенные вами фильтр.
Третья вкладка Главная, вкладка содержит настройки ленты, в которой можно указать будут ли новости из этой ленты допускаться на главную страницу сайта, да или нет, если нет, то все новости будут публиковаться просто с соответствующий раздел. Так же перечислены фильтры при попадании под которые новости этой ленты не будут публиковаться на главной.
 Четвертая вкладка Контент, на ней мы остановимся и заострим внимание поподробнее, так как в этой вкладке содержатся настройки необходимые для правильно работы парсера.
Четвертая вкладка Контент, на ней мы остановимся и заострим внимание поподробнее, так как в этой вкладке содержатся настройки необходимые для правильно работы парсера.
 1. Как следует из описания «Опция оговаривает, будет ли компонент автоматически публиковать новостной контент для просмотра во фронт-энде сайта» , иными словами публикация будет автоматом без модерации админом. Я считаю, что все же перед публикации лучше хотя бы бегло смотреть содержимое новости, т.к. может в текст попать нежелательный html код или еще что..
1. Как следует из описания «Опция оговаривает, будет ли компонент автоматически публиковать новостной контент для просмотра во фронт-энде сайта» , иными словами публикация будет автоматом без модерации админом. Я считаю, что все же перед публикации лучше хотя бы бегло смотреть содержимое новости, т.к. может в текст попать нежелательный html код или еще что..
2. «Максимальное количество элементов для загрузки — За один сеанс импорта ленты, в базу данных Joomla! будет записано не более элементов, чем оговорено в этом поле.» — если импорт идет из RSS потока то не стоит указывать число большее чем новостей в потоке, несмотря на то, что парсер защищен от ошибок пользователя, все же часто бывают ошибки в его работе, так что лучше подстраховываться.
3. далее
4. Указываем рубрику и Категорию в которую будут помещены новости из этой ленты.
5. Настраиваем Анонс новости, тут надо определиться откуда стоит брать анонс из RSS потока или просто брать первый абзац самой новости, по желанию, но часто бывает что в RSS ленте идет уникальный анонс новости отличный от текста новости, и поэтому в каких то случаях стоит брать именно его, хотя и минусы есть анонс из RSS ленты может быть очень коротким, вплоть до нескольких слов.
6. Урезать анонс до определенного ко-во символов, вроде все понятно, но опять же стоит обратить внимание на детали – предположим что анонс берется из RSS, и его длина 100 символов, если же в этом поле указать обрезать анонс на 250символе, то могут начаться жуткие глюки с парсером, когда как через раз. Так же анонсы в RSS ленте как правило разной длины, один 500 второй 100 символов, так, что стоит подстраховаться. Стоит задуматься о настройке 5 пункта, возможно лучше все таки использовать анонс из текста новости…. В этом примере мы так и сделаем.
7. Искать конец предложения, можно выставлять ДА, и парсер будет искать, но замечу концом предложения он считает точку, а если точки нет, и не будет аж в нескольких абзацах, то в анонс может попасть вся новость… такое бывало не раз.
8. Замыкать тэги. Рекомендую ставить НЕТ, так как теги мы все равно будет вырезать фильтрами… В описании этой опции так же сказано, что глюкам тут есть где поселиться.
9. Копировать полный текст новости, эта функция оговаривает откуда будет браться новость из потока RSS или из страницы полной новости, рекомендую второй вариант т.е. ДА, так как в RSS потоке новость может быть ограниченна так же несколькими словами.
10. Срок жизни новости (дни), тут все понятно
11. Дата создания из ленты, рекомендую Нет, в описании все изложено
12. Далее*
13. Далее*
14. Далее*
* Автор, настройки это небольшой подгруппы опций, можно не трогать или настраивать так как хочется, на работу парсера они не влияют… исключительно для удобства и соблюдения авторства.
Пятая вкладка Картинки, содержит в себе опции для настройки отображения картинок в анонсе и основном тексте новости, можно задать максимальную ширину и высоту картинки как для анонса так и для самой новости, при этом размер картинки будет изменен специальным скриптом, в результате получится уникальная картинка (для поисковиком), что положительно для SEO.

В этой вкладке так же все понятно и очевидно, но есть одна деталь, вернее одно поле на котором остановимся:
1 . Каталог хранения картинок, тут достаточно просто прописать любое слово английскими буквами, например «poeziya» в результате парсер создаст каталог с таким названием и его путь будет таким /images/stories/poeziya/ если не задать имя каталога для картинок, то картинки просто не будут сохранятся, хоть парсер и должнен сохранять их в каталог по умолчанию, часто этого не происходит, так же бывают ошибки с картинками из-за неправильно выставленных прав на каталог /images/stories/, в результате записать в него и создать в нем подкаталог парсер не может, рекомендованные права 755 или 777
2. Вырезать картинки из анонса, вместе картинок из анонса этот опция так же вырежет картинки из основной новости, так как часто картинка в новости находится в начале, в итоге картинки не будет не в анонсе не в тексте новости, рекомендую ставить НЕТ
3. Первую картинку в анонс, рекомендую ставить ДА, первая картинка отправится в анонс и будет иметь указанный максимальный размер.
Далее все настройки логичны и понятны.
Важно! С картинками тоже очень часто бывают проблемы, многое зависит непосредственно от шаблона сайта, его дизайна и заданных стилей.
Пример распространенного глюка(распространяется на анонс): Предположим что после работы парсера, на главной странице отображаются теперь уже наши новости – вернее их анонсы, с картинками и кнопочкой Подробнее, для перехода к просмотру полной новости. Все вроде красиво и как нам надо, но при переходе к полной новости мы видим и анонс и текст новости, и в случае если картинка и текст анонса взяты из текста новости, получится что текст полной новости частично повторяется… Это происходит из-за не предусмотренности анонсов шаблоном сайта, или же если анонсы реализованы в шаблоне каким либо особым методом, и т.д. С таким я очень часто сталкивался.. Так же в самих настройках джумлы бывают неправильно выставлены опции для отображения анонса, или установлены доп. Плагины и прочее.
Шестая вкладка Вставка, Вставить HTML в тело новости. (можно пропустить) Тут так же есть кое какие особенности. Как и написано в описании полей, не стоит сюда кривого и неправильно написанного кода.
Заданная точка может быть любым словом или тегов в тексте взятой новости с сайта донора, но на некотором хостинге при некоторых условиях заданная точка не может состоять из русских букв. Такая заданная точка просто не будет найдена и вставка не будет произведена.
Вообще эта опция очень полезна. С помощью ее можно например вставлять в конце каждой новости Ссылку на источник, или в самом тексте новости какой ни будь рекламной код.
Седьмая вкладка Уникализация, (можно пропустить), свое образный синонимайзер. Которым видимо гордятся разработчики парсера =) Но практичность его применения под сомнением, во первых это отражается на скорости работы парсера, который и без того сильно нагружает хост. Во вторых синонимайз плохо читаем, и для СДЛ такой контент не годиться, уж лучше плагиат но со ссылкой на первоисточник. Хотя кому как.
И так тут с настройкой все понятно, список синонимов можно подгрузить из дополнительного фала или же вписать самому в первое большое поле, синонимы задаются в следующем формате:
слово=синоним1|синоним2|синоним3
(в конце черту | не ставим, могут возникнуть глюки )
Восьмая вкладка Логин , (можно пропустить), настройка граббера для автоматического залогивания на сервере донора если такая процедура вообще требуется, хотя и такое бывает, например если полная новость доступна только зарегистрированным пользователям.
Тут все понятно, но опять же что касается заполнения полей этой вкладки, то эта процедура уникальна для каждого источника, перед заполнением полей необходимо изучить всю работу сайта донора, форму логина, все переменные, а так же передаваемые параметры куки и прочее.
Работа с этими настройками требует знаний больших чем просто – пользователь, а так же описывания примера настройки этих опций займет немало времени, так что я ограничиваюсь кратким описанием.
Девятая вкладка Шаблоны, включает в себя функции для создания и настройки шаблонов фильтров, которые будут применены к заголовку, тексту или имени автора новости. Можно задать шаблоны замены или удаления тегов, частей текста из новости и т.д. На этой кладке остановимся и так же разберем ее поподробнее.
Для настройки шаблонов фильтров, желательно знать азы работы с регулярными выражениями, для того что бы правильно задать маску фильтра – шаблона.
Шаблон состоит из следующих значений: (несмотря на то что там все понятно, опишу их)
— поиск : по этой маске будет искаться текст, и при совпадении будут производиться действия
— замена: указывается значение на которое будет заменяться найденный текст, при пустом поле, будет происходить просто удаление найденного текста
— кол-во замен, если оставить поле пустым, то замена будет производиться по всему тексту.
К настройке этой вкладки как правило следует переходить уже после настройки последней десятой вкладки «Обработчик», так, что к описанию настройки шаблонов вернемся позже.
Десятая последняя и основная вкладка Обработчик, перед настройкой параметров парсера в этой вкладке необходимо сохранить ленту, для этого вверху достаточно нажать кнопку «Применить», а уже после этого приступать к ее настройке.
И так первый шаг, жмем кнопку «Тест»

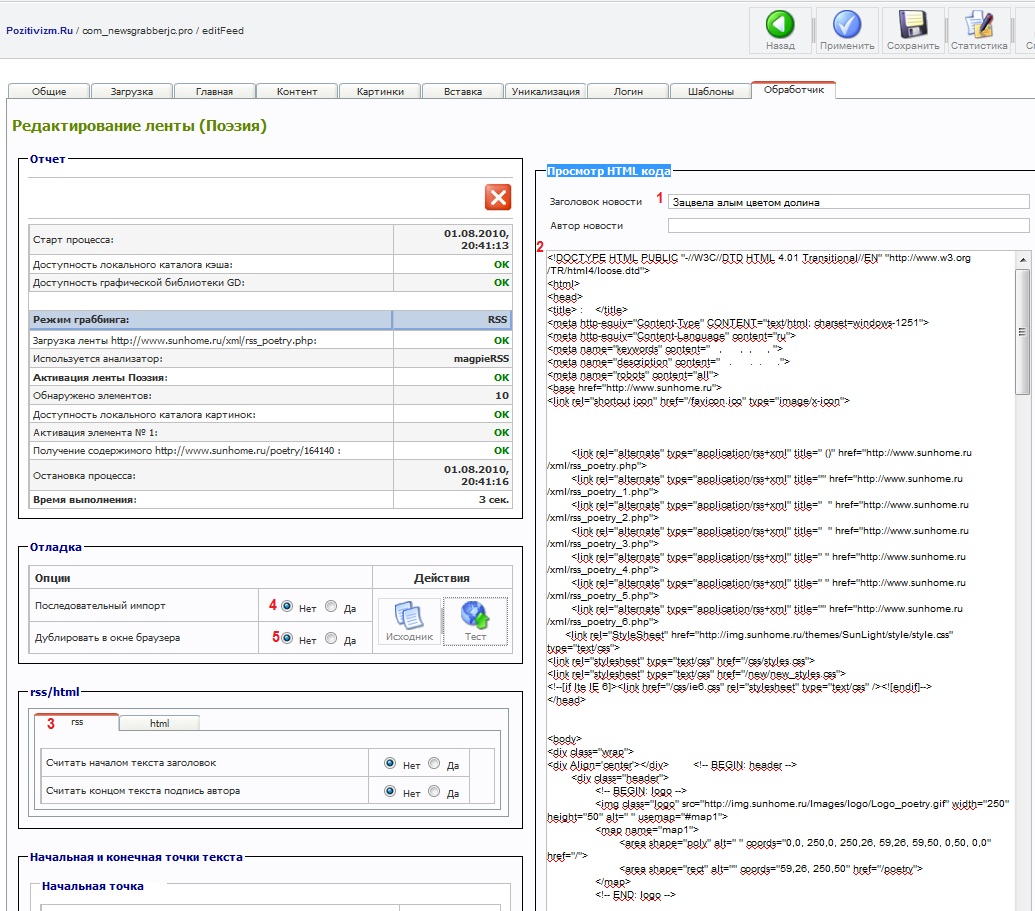
После чего парсер начинает свою работу в тестовом режиме, это необходимо для его настройки и отладки ленты. Работает парсер по описанному мною в начале этого мануала алгоритму, т.е. считывает RSS ленту, берет из первой новости в rss потоке все данные в том числе и ссылку на полную новость, затем парсер идет по полученной ссылке и загружает весь код страницы, и в итоге выводит его в поле «Просмотр HTML кода» картинка справа :

Итак, тестовый заход выполнен, код странице вместе с новостью, заголовком и картинкой взят. На картинке отмечено поле цифрой 2, в нем вы видите весь код страницы с которым нам теперь предстоит работать, выделать из него текст новости, картинку, и убирать все лишнее, вне ненужные нам теги и скрипты, а так же остальной ненужный текст.
Под цифрой 1, на картинке мы видим поле «Заголовок новости», там уже прописался заголовок новости, который был взят не из кода страницы, а из RSS потока (при грабинге HTML ленты заголовок будет браться уже из кода новости, или из названия ссылки на эту новость, т.е. анкор ссылки)
Под цифрой 3 замечу выбрана вкладка RSS, это непросто вкладки RSS и HTML это своеобразный переключатель режима работы парсера, если выбрана вкладка RSS работает в соответствующем режимы, так же и с HTML.
Под цифрами 4 и 5, Последовательный импорт и Дублировать в окне браузера, настройки для удобства тестирования работы парсера с этой лентой, с ними можно поиграться, попробовать в таким или ином режиме, практической разницы они не имеют.
И так продолжим настраивать ленту и в данной вкладке перейдем к полям «Начальная и конечная точки текста», тут мы видим два поля (вернее их 4, но будем считать два), рис ниже:

Начальная точка – здесь указывается часть HTML кода страницы начиная с которого парсер начнет брать новость, весь код до этой точки будет отброшен.
Конечная точка – часть кода встретив который парсер поймет что достигнут конец новости, после этой точки весь последующий код будет отброшен, чтобы немешался.
 Для определения начальной и конечной точки, нам необходимо в окне справа «Просмотр HTML кода» отыскать эти самые точки, для этого нам необходимы базовые знания HTML, и так чтобы найти начальную и конечную точку, нужно как минимум знать как же выглядит сама новость, т.е. нужно знать текст новости, иначе как разобраться в этом завале тегов и текста, что есть тут текст новости.
Для определения начальной и конечной точки, нам необходимо в окне справа «Просмотр HTML кода» отыскать эти самые точки, для этого нам необходимы базовые знания HTML, и так чтобы найти начальную и конечную точку, нужно как минимум знать как же выглядит сама новость, т.е. нужно знать текст новости, иначе как разобраться в этом завале тегов и текста, что есть тут текст новости.
Для этого немножко схитрим, откроем в браузере новую страницу и перейдем по ссылке (для примера используется браузер firefox 3.6) ленты rss — http://www.example.ru/xml/rss_poetry.php
В итоге увидим следующую картину:

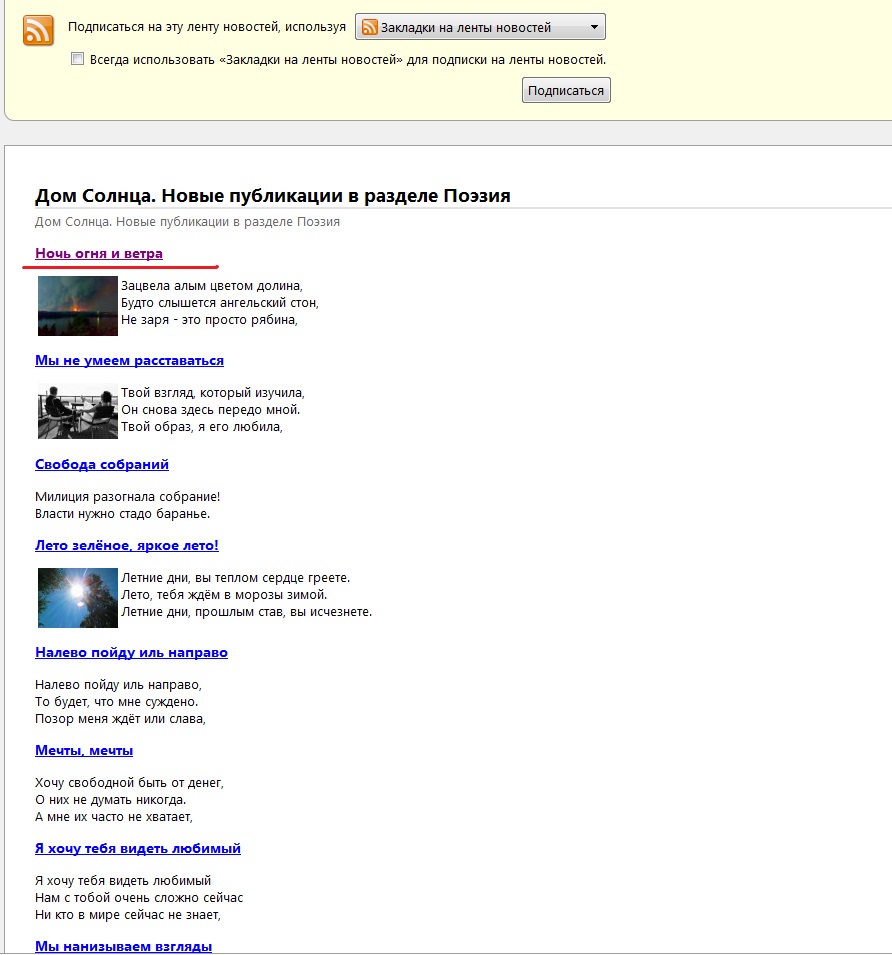
Браузер откроет поток rss ленты и выведет все ее содержимое, далее нам необходимо перейти по ссылке на первую новость, в данном примере «Ночь огня и ветра», после перехода на страницу с полной новостью, мы сможем ознакомиться с ее текстом, рис ниже:

Итак как мы видим текст новости следующий:
«За одну ночь в Нижегородской области было уничтожино пожарами около 700 жилых домов.
Зацвела алым цветом долина,
Будто слышется ангельский стон,
Не заря — это просто рябина,
Зачитала последний псалом.»
Все эти манипуляции мы проделывали для того, что без особых затруднений отыскать в куче HTML кода и текста, саму  новость. И так возвращаемся в настройки парсера во вкладку «Обработчик» в поле «Просмотр HTML кода» и уже ищем этот текст (можно воспользоваться поисков браузера правка/найти, для удобства):
новость. И так возвращаемся в настройки парсера во вкладку «Обработчик» в поле «Просмотр HTML кода» и уже ищем этот текст (можно воспользоваться поисков браузера правка/найти, для удобства):
Текст новости мы нашли, теперь нужно определиться с начальной и конечно точкой, как правило это должен быть уникальный код страницы, в противном случае придется задавать № от начала и № от конца, а эти параметры в каждой новости могут колебаться и в результате парсер будет глючить, так что лучше найти уникальные Начальную и Конечную точку, в нашем примере мы нашли такие фрагменты кода, которые больше негде не повторяются:
Начальная точка: <div class=’articletext’>
Конечная точка: <!— END: article —>
Сохраняем результат, и снова жмем кнопку ТЕСТ, если все сделали правильно, начальная и конечная точка заданы верно, мы увидим следущее:

В поле «Просмотр HTML кода» теперь отображается именно тот фрагмент страницы в котором есть текст новости ссылка на картинку в теге <img…> (пример <img src=’http://img.example.ru/UsersGallery/poetry/0820101211952.jpg’)
Следующая настройка будет заключаться в коррекции ссылки на картинку, допустим ссылка на картинку в коде страницы новости будет иметь вид: не http://img.example.ru/UsersGallery/poetry/0820101211952.jpg, а /UsersGallery/poetry/0820101211952.jpg… В первом случае парсеру все ясно, он просто зайдет по указанному урлу и скачает картинку, но во втором случае урл картинки не абсолютный а относительный, по этому в поле URL картинок, нужно прописать адрес сайта донора:
![]()
Теперь парсер знает что картинки по указанному неполному пути стоит искать на сервере http://www.example.ru/.
Так же замечу, что на одном сайте бывают новости картинки в которых расположены как на самом сервера так и на удаленном, т.е. в одних новостях могут использоваться относительные пути, а в других абсолютные, в таком случае стоит указывать значение URL картинок. По задумке парсер должен определять, относительные и добавлять к ним этот параметр, а абсолютные обрабатывать так как есть, но на практике замечены глюки в его работе, таким образом что он работает только либо с абсолютными либо только с относительными…
И так базовая настройка ленты закончена. Несмотря на то, что в тексте новости осталось много мусора, теперь мы проверим как работает наш парсер. Жмем кнопку сохранить и переходим к списку лент, далее ставим галочку на против нашей новой ленты и жмем кнопку «Импорт», результат должен быть следующим:

Тут все перепроверим.
Картинок обнаружено: 2 (значит код с урлом картинки присутствует в тексте новости, и урл картинки верный)
Картинок скопировано:2 (значит каталог для хранения картинок создан успешно, проблем с правами нет, все отлично копируется)
Вся остальная информация нам понятно, новостей скопировано – 2е, именно так как мы и указали в настройках ленты, брать по две новости за раз, доступность ленты, и необходимые компоненты установлены. Импорт прошел успешно. Обе новости опубликованы на сайте без нашей модерации.
Но еще не все, дело в том, что в тексте новости еще все остаются ненужные нам теги, которые портят ее вид, и прочее.
И так вернемся к настройкам этой ленты, и теперь уже перейдем во вкладку «Шаблоны», как мы видим на рисунке Images/img1.10.8, в тексте новости есть следующий код:
<style>.bgbanner {padding-top:4px; padding-bottom:5px; padding-left:8px} .begun_adv_sys {display:none !important;} </style>
Его стоит удалить из текста новости, для этого создадим новый шаблон:
![]()
Тут нам понадобятся познания принципов работы регулярный выражений (примеры настройки на картинке выше), если с этим проблемки, то можно воспользоваться уже готовыми шаблонами идущими в составе греббера.
Теперь нужно активировать новый шаблон, чтобы он стал применяться парсером к новостям. Для этого в новом появившемся поле кликаем на синенькую галочку, рис ниже

Так же активируем второй шаблон, для удаления всех скриптов из текста новости.
Шаблоны активированы, но пока не работают, необходимо задать

порядок выполнения шаблонов, теперь перейдем во вкладку «Обработчик», и промотаем немного вниз страницы, слева мы видим поле «Шаблоны обработчика»
Зададим порядок, проставим значения 1 и 2 соответственно, после чего сохраним все наши изменения, теперь можно нажать кнопку ТЕСТ и убедиться что текст новости очищен от левых ненужных нам тегов. И не будет портить нам дизайн нашего сайта =)

Можно так же очистить новость и от остальных тегов, задав соответствующие шаблоны.
Теперь сохраняем новость, переходим к списку лент, ставим галочку на нашу ленту и жмем кнопку ИМПОРТ, после того как парсер отработает идем на главную страницу сайта или в админке в раздел Материалы/Все материалы и смотрим на полученный результат!!!
Отображение новостей так же можно настраивать через CSS, в текст новости можно вставлять нужные нам теги форматирования и так далее.
Видео ролик по настройке NewsGrabber JC, в качестве источника взята лента в формате RSS
Настройка ленты, в качестве источника HTML


Похожие записи
19 комментариев to “Интрукция по настройке NewsGrabber JC для Joomla”
Оставить комментарий
Full Stack
Senior, Architect



предложить оффер

{kind=link}
{kind=link}
{kind=link}
- Главная (новая)
- jQuery: как получить значение атрибута?
- PHP работа с изображением, класс SimpleImage
- PHP date() — вывод русского месяца
- Комментарии на PHP, Ajax, mySQL
- Nginx редирект на другой сервис с сохранением URL спросил (а) Сергей
- Исполнитель пропал, почему такое случается и понять с кем работать? спросил (а) Артем
- Можно ли WordPress считать универсальным движком? спросил (а) Андрей
- Что такое самописный скрипт или CMS? спросил (а) Антон
- Как при поиске в linux используя grep, добавить исключения? спросил (а) Алексей
- к записи Обзор Insurance CMS — платформы для сайтов по страхованию
- к записи Консольный скрипт(JavaScript) для автоматических заказов на OZON
- к записи Консольный скрипт(JavaScript) для автоматических заказов на OZON
- к записи Как создать Telegram-бота с авторизацией через сайт
- к записи PHP скрипт: каталог закладок на сайты
- к записи Валидация на PHP
- к записи Сколько зарабатывают в бизнесе на совместных покупках
Archive
- +2026 (4)
- Июль 2026 (1)
- Июнь 2026 (1)
- Февраль 2026 (1)
- Январь 2026 (1)
- +2025 (28)
- Июль 2025 (1)
- Май 2025 (1)
- Апрель 2025 (7)
- Март 2025 (4)
- Февраль 2025 (9)
- Январь 2025 (6)
- +2024 (35)
- Декабрь 2024 (7)
- Ноябрь 2024 (13)
- Октябрь 2024 (8)
- Сентябрь 2024 (1)
- Август 2024 (5)
- Май 2024 (1)
- +2023 (27)
- Ноябрь 2023 (1)
- Октябрь 2023 (13)
- Сентябрь 2023 (10)
- Апрель 2023 (1)
- Март 2023 (1)
- Февраль 2023 (1)
- +2022 (21)
- Декабрь 2022 (11)
- Ноябрь 2022 (1)
- Май 2022 (2)
- Апрель 2022 (2)
- Март 2022 (3)
- Февраль 2022 (1)
- Январь 2022 (1)
- +2021 (17)
- Декабрь 2021 (5)
- Ноябрь 2021 (2)
- Июль 2021 (1)
- Июнь 2021 (2)
- Май 2021 (5)
- Апрель 2021 (1)
- Март 2021 (1)
- +2020 (20)
- Декабрь 2020 (6)
- Сентябрь 2020 (2)
- Август 2020 (1)
- Июль 2020 (2)
- Май 2020 (2)
- Апрель 2020 (2)
- Март 2020 (2)
- Февраль 2020 (1)
- Январь 2020 (2)
- +2019 (18)
- Декабрь 2019 (3)
- Ноябрь 2019 (2)
- Октябрь 2019 (2)
- Сентябрь 2019 (1)
- Август 2019 (2)
- Июль 2019 (1)
- Июнь 2019 (1)
- Апрель 2019 (2)
- Март 2019 (1)
- Февраль 2019 (3)
- +2018 (44)
- Декабрь 2018 (4)
- Ноябрь 2018 (7)
- Октябрь 2018 (8)
- Сентябрь 2018 (1)
- Август 2018 (4)
- Июль 2018 (5)
- Май 2018 (3)
- Апрель 2018 (7)
- Март 2018 (1)
- Февраль 2018 (2)
- Январь 2018 (2)
- +2017 (19)
- Декабрь 2017 (2)
- Ноябрь 2017 (1)
- Октябрь 2017 (1)
- Сентябрь 2017 (2)
- Июль 2017 (1)
- Июнь 2017 (1)
- Май 2017 (2)
- Апрель 2017 (3)
- Март 2017 (2)
- Февраль 2017 (1)
- Январь 2017 (3)
- +2016 (36)
- Декабрь 2016 (3)
- Ноябрь 2016 (3)
- Октябрь 2016 (2)
- Сентябрь 2016 (3)
- Август 2016 (7)
- Июнь 2016 (3)
- Май 2016 (3)
- Апрель 2016 (3)
- Февраль 2016 (1)
- Январь 2016 (8)
- +2015 (36)
- Ноябрь 2015 (5)
- Октябрь 2015 (4)
- Сентябрь 2015 (1)
- Август 2015 (8)
- Июнь 2015 (1)
- Май 2015 (4)
- Апрель 2015 (8)
- Март 2015 (3)
- Февраль 2015 (2)
- +2014 (26)
- Ноябрь 2014 (2)
- Октябрь 2014 (5)
- Сентябрь 2014 (6)
- Июль 2014 (1)
- Июнь 2014 (2)
- Май 2014 (3)
- Апрель 2014 (6)
- Февраль 2014 (1)
- +2013 (27)
- Декабрь 2013 (2)
- Ноябрь 2013 (1)
- Октябрь 2013 (1)
- Август 2013 (1)
- Июль 2013 (3)
- Июнь 2013 (10)
- Май 2013 (1)
- Апрель 2013 (2)
- Февраль 2013 (3)
- Январь 2013 (3)
- +2012 (41)
- Декабрь 2012 (2)
- Ноябрь 2012 (3)
- Октябрь 2012 (7)
- Сентябрь 2012 (2)
- Август 2012 (1)
- Июль 2012 (3)
- Июнь 2012 (2)
- Май 2012 (6)
- Апрель 2012 (2)
- Март 2012 (7)
- Февраль 2012 (5)
- Январь 2012 (1)
- +2011 (57)
- Декабрь 2011 (6)
- Ноябрь 2011 (2)
- Октябрь 2011 (3)
- Сентябрь 2011 (5)
- Август 2011 (4)
- Июль 2011 (3)
- Июнь 2011 (3)
- Май 2011 (3)
- Апрель 2011 (4)
- Март 2011 (10)
- Февраль 2011 (5)
- Январь 2011 (9)
- +2010 (43)
- Декабрь 2010 (7)
- Ноябрь 2010 (21)
- Октябрь 2010 (14)
- Сентябрь 2010 (1)
Свежие записи
- Установка драйвера АТОЛ-30ф на Ubuntu 24.04 18.07.2026
- Распознавание QR-кодов 01.06.2026
- Подключение АТОЛ-30ф к серверу на Linux 14.02.2026
- Запрет пробуждения ПК от различных устройств в Windows 10/11 31.01.2026
- Список всех BIN российский банков в JSON 10.07.2025






Спасибо Роме! За проделанную работу по созданию видео и подробного мануала! И отдельное спасибо за настройку! Все быстро,качественно и без суеты! Советую всем!
спасибо!
А где скачать сам грабер?
А как ее на саму joomla установить,неустанавливается-выдает ошибки?
По вопросам приобретения и устранению неполадок стоит обращаться к разработчикам. Правда замечу, что отвечают они не очень охотно, порой переписка затягивается на длительное время.
Можно поискать и нуленую версию в сети, но кроме всякого старья я честно говоря не встречал((
А как ее на саму joomla установить,неустанавливается-выдает ошибки?
какие именно ошибки? пишите, попробуем помочь
А где мануал по настройки ленты HTML?
У меня вот возникает проблема, настроил на хтм, по этому посту, все вроде нормально, но копирует только одну картинку! хотя обнаруживает больше.
+ во вкладке обработчик пишет анонс, но почему то его на сайте анонса нет, только полную новость можно просмотреть.
Собственно небольшой пост по настройке HTML ленты, заключительная стадия,
http://rche.ru/498_nastraivaem-newsgrabber-jc-html-lentu-novostej.html
все остальное описано в этом мануале.
Возможно проблема в неправильно заданных точках начала-конца, или еще как вариант не правильно настроены шаблоны. Отображение анонса в некоторых случаях зависит еще и от шаблона (template) установленного на сайте.
В последней версии граббера добавлены новые фишки которых не было в той версии, по которой написан данный мануал. Это я к тому, что последняя версия стала на мой взгляд более не предсказуемой в поведении.
Да я уже даже пробовал ставить стандартный шаблон, все тоже самое. со стандартной РСС лентой все выходит, а вот с ХТМЛ картинка грабиться только 1, все остальные не хотят. ну и с анонсом такая же беда, в стандартной ок, в хтмл анонс в ТЕСТЕ есть, но на сайте нет.
Хотел еще спросить, что такое начальная и конечная точка контейнера!?
Начальная и конечная точка контейнера — это точки в html документе обозначающие от куда и до куда парсер берет контент. Т.е. задаем парсеру это точки ввиде отрывков html кода документа, встретив которые парсер будет знать, что «отсюда» следует начинать брать контент, а вот «тут» прекращать. К сожаление как это все описать более понятным способом не знаю))
Вы вроде бы достаточно хорошо все описали=)
Оказывается, компонент не грабил картинки по причине того, что небыл выдержен формат w3c
А вот как можно организовать афишу при помощи граббера, есть идеи?
Думаю тут ни чего сложного нет, создаем несколько лент, возможно с одного источника, но при этом с разных категорий. Далее на сайте создаем разделы, категории, настраиваем ленты, чтобы они раскладывали весь спарсеный контент по соответствующим категориям. Ставим все на cron и афиша готова))
Вот я тоже к этому решению пришел, но встает вопрос, как быть с датами?
1) Ведь дата ставится — создания материала, а не время проведения мероприятия.
2) К хорошей афише должен быть календарь? Где его взять? Да и к тому же стандартные календари блогов, ставят дату создания материала «единожды», а если мы публикуем выставку, кино, а такие мероприятия длятся не один день.
И вот на этом мои мысли закончились, и попытки создать прирвались….
Да верное, проблем при решении такой задачи много, но я честно говоря думаю, что newsgrabber вообще не предназначен для решения именно такой задачи, если он ставится на стандартную joomla. Чтобы организовать нечто подобное, на мой взгляд придется значительно дорабатывать всю систему полностью, писать доп скрипты и прочее.
Нашел решение!
Попался наруки календарь материалов, который выдает как дату создания материала, или опционально дату провдения события (устанавливается вручную при добавлении мероприятия в календарь). Правда вся эта система получается не автоматизированной, а механизированной. Но во всяком случае избавляет нас от ручного набора материала, даже в том же Евент-листе.
Не долгим было мое счастье,компонент Jalendar, оказался не совсем рабочим, или я что-то не понял, вроде все выставил, а он не фурычит, не показывает материал хоть убей, а так бы получилась очень даже хорошая афиша
На сайте новости автоматически почему-то не публикуются. При нажатии кнопки импорт в админку новости попадают, а в автомате нет. Сразу скажу — Публиковать контент автоматически — стоит ДА. Почему это возможно, уже все перепробовал, не помогает. Подскажите, плиз.
Вроде как авто-режим должен быть инициализирован по запросу CRON-TAB, иными словами, что бы автоматом грабилось и складывалось в базу, нужно запустить скрипт, а это должен в свою очередь сделать Cron, который запускает нужный URL адрес и вызывает скрипт — например каждый час. Как его настроить почитайте доки у своего хостера. При этом какой именно URL вызывать, также почитайте в доках к грабберу.